Яндекс запустил Нейро. Рассказываем, как он работает
Сегодня мы запустили сервис Нейро — новый способ поиска ответов на вопросы. Пользователь может задать Нейро любой вопрос, а тот сам подберёт подходящие материалы в Поиске, проанализирует их и соберёт найденную информацию в одном ответе, подкрепив его ссылками на источники. Нейро объединил опыт Яндекса в создании поисковых технологий и больших языковых моделей.
Меня зовут Андрей Сюткин, и я отвечаю за ML-трек в Нейро. В этой статье покажу, как выглядит архитектура Нейро и как формируются ответы на технологическом уровне. Ну и, конечно же, поговорим о нейросетях, в том числе о YandexGPT 3, без обучения которых новый сервис просто не увидел бы свет.
Что такое Нейро
Яндекс был основан как сервис для поиска в интернете и вот уже 27 лет помогает людям находить информацию. На текущий день мы знаем о более чем 130 миллиардах страниц и умеем находить в них ответы за 400 миллисекунд для многих тысяч запросов в секунду.
Все эти годы поиск ассоциировался со списком «синих ссылок». Пользователь вводил запрос, получал в ответ список ссылок, а дальше уже сам разбирался в них. Со временем поисковые технологии развились настолько, что для абсолютного большинства запросов люди перестали заглядывать даже на вторую страницу результатов, но базовый подход оставался неизменным.
Мы понимали, что пользователи зачастую ищут не просто ссылки, а хотят решить какие-то свои задачи. И мы стремились помочь людям в этом. Так в поиске начали появляться разного рода «обогащения». Например, сниппеты — фрагменты текста под каждым сайтом на выдаче — упрощали выбор страницы. Позднее мы добавили быстрые ответы, которые отвечали на простые вопросы сразу на странице с результатами, указывая в качестве источника информации один конкретный сайт. Для многих узких срезов были разработаны отдельные тематические блоки, которые упрощали решение конкретных, узких задач. Например, разработчики могли уже
с блоком, который содержал структурированный ответ со Stack Overflow. Все эти «фишки» экономят время и помогают с решением задач. Но все они лишь дополняют тот самый список синих ссылок.
И вот сейчас мы хотим показать Нейро. Это новый сервис для поиска ответов, который на текущий момент доступен в приложении Яндекс и Яндекс Браузере. Нейро способен отвечать на вопросы, для которых обычно нужно изучить несколько источников из интернета. Например, «какие растения могут жить в тёмной комнате дома и не требуют ежедневного полива» или «стоит ли ехать осенью в Карелию и чем там заняться». Нейро проанализирует запрос, найдёт в поиске список релевантных ссылок, извлечёт из материалов информацию и скомпилирует готовый ответ.

Нейро берёт факты не из памяти модели, а из источников в интернете. Это значит, что в его ответах содержится свежая и актуальная информация, даже если она появилась всего несколько часов назад. Каждый факт в ответе подкреплён ссылкой на источник. Благодаря таким ссылкам пользователи смогут углубиться в интересующую тему, а площадки — получить дополнительный трафик. Если владелец сайта не хочет, чтобы веб-страницу использовали в качестве источника ответов для нового сервиса, он может установить директиву в robots.txt. При установке этой директивы сайт перестанет использоваться в качестве источника данных как для Нейро, так и для быстрых ответов в Поиске (подробнее — в
Вебмастера).
Когда-то всем нам приходилось учиться языку поисковых запросов. Яндекс даже проводил
! Теперь спрашивать Нейро можно естественным языком — так, как вы формулируете вопрос в голове. Более того, Нейро учитывает контекст предыдущих вопросов в рамках диалога. Если вы хотите доуточнить ответ, задать вопрос в продолжение темы или добавить новые вводные, вы можете сделать это в диалоговом формате.
А если не хватает слов — можно дополнительно использовать картинки.
Теперь поговорим о том, как всё это работает.
Две крайности
С помощью LLM-моделей можно отвечать на произвольные вопросы пользователей. Но есть два крайних состояния.
Первая крайность. Найдём страничку в интернете, которая содержит ответ на вопрос. LLM-модель получает на вход запрос пользователя, текст страницы и задание суммаризировать исходный текст в ёмкий ответ. При этом важно, чтобы модель не добавляла отсебятину, то есть не галлюцинировала.
Что хорошо: такой ответ подтверждён источником и его легко перепроверить.
Что плохо: если на запрос пользователя не нашёлся сайт с прямым ответом, тогда и ответить нечем, а значит, страдает полнота фактов. Такое решение будет не сильно полезнее, чем простой список ссылок.
Вторая крайность. Давайте просто зададим модели любой вопрос и попросим её ответить из своей памяти.
Что хорошо: можно отвечать вообще на любой вопрос.
Что плохо:
- непонятно, что модель вспомнила, а что выдумала (как верить такому ответу?);
- знания берутся из весов, а значит, модель должна быть очень большой;
- нет знаний о недавних событиях;
- нет знаний о крайне редких фактах.
Такие модели полезны для генерации идей и написания текстов, но вот использовать её в качестве источника знаний вряд ли стоит.
Каждое из крайних состояний сделать относительно просто. Но оптимум находится где-то между ними. Хочется, чтобы модель умела отвечать на произвольный вопрос, но при этом её ответ был подкреплён источником, и его легко было проверить. Вот как мы решили реализовать это:
- на вход модели подаётся вопрос пользователя подходящие для ответа сайты из интернета;
- модель не отвечает фактами из памяти, а берёт их только из источников;
- модель имеет право делать корректные выводы из фактов, но не имеет права выдумывать факты;
- любой кусочек ответа должен быть подтверждён источником, его должно быть легко проверить.
И это оптимальное решение — большой челлендж для LLM-моделей. Подать на вход в модель запрос пользователя и тексты из интернета не сложно. Сложно добиться того, чтобы модель использовала эту информацию и делала на её основе выводы, при этом не выдумывая факты и избегая ошибочных заключений.
Об этом челлендже и пойдёт дальше речь.
Архитектура Нейро
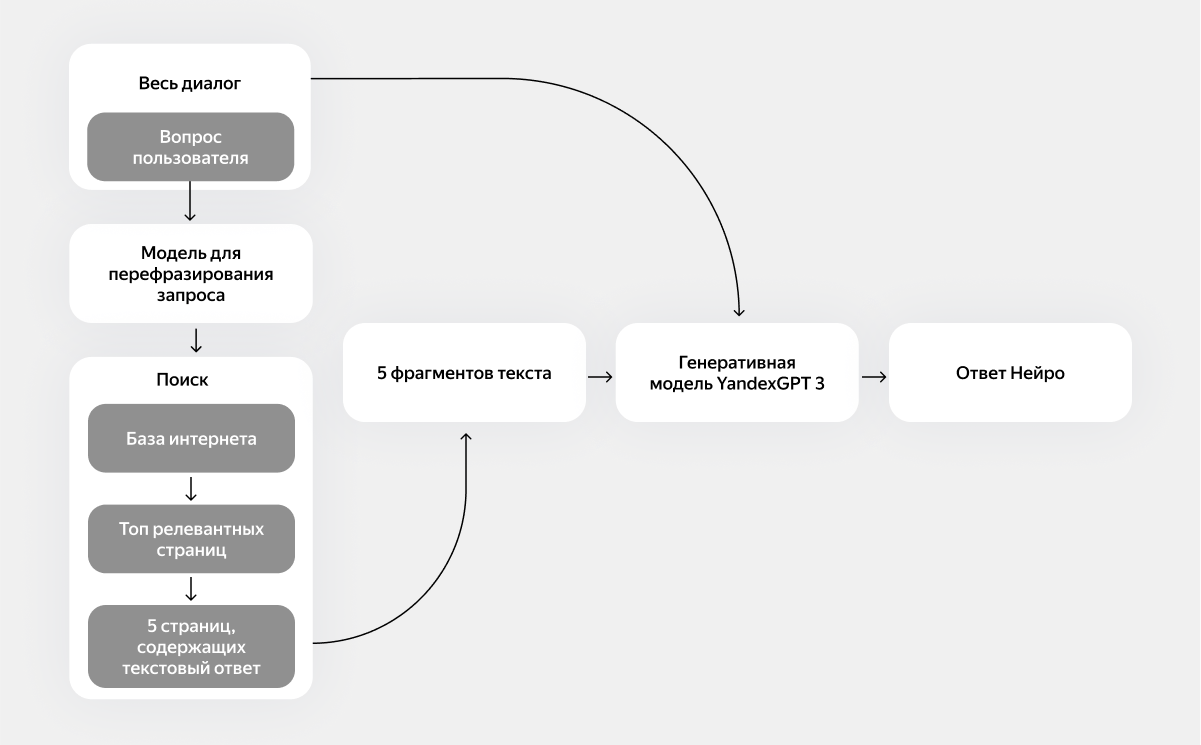
Общая архитектура решения выглядит так:
- В контексте диалога с Нейро пользователь задаёт какой-то вопрос.
- Вопрос пользователя трансформируется в поисковый запрос.
- Поисковая система находит топ релевантных документов на запрос пользователя.
- Из этого топа выбираются пять документов, на основе которых получится построить текстовый ответ.
- Специализированная генеративная модель из семейства
получает на вход диалог, запрос пользователя и полезные фрагменты текстов из пяти документов.
Перефразирование запросов (рефразы)
Пользователь ведёт диалог с Нейро. В процессе диалога он может что-то уточнить или перефразировать. Без контекста диалога такой запрос может быть непонятным.
Пользователь:
«Самая популярная книга Чака Паланика»
Нейро:
«Самый знаменитый роман Чака Паланика — «Бойцовский клуб». По нему в 1999 году был снят одноимённый фильм. … »
Пользователь:
«Когда она написана»
Очевидно, по последнему вопросу («Когда она написана») без контекста нельзя сформулировать поисковый запрос «когда была написана книга «Бойцовский клуб» Чака Паланика».
А ещё вопрос пользователя может содержать ошибки, опечатки, лишнюю информацию или быть очень непонятно сформулирован. Его перефразирование позволяет более эффективно применять поиск.
Задача этого этапа — сформулировать один ёмкий поисковый запрос. Технически эта задача реализуется небольшой версией модели YandexGPT 3. На вход она принимает последние 16 реплик диалога и по ним формирует запрос, с которым нужно пойти в поиск, чтобы найти источники информации. Эта модель специально обучена извлекать поисковый запрос пользователя из контекста диалога с Нейро. Обучение модели было многоэтапным.
- Сперва мы описали инструкцию вида «есть диалог пользователя с сервисом, напиши поисковый запрос, который поможет ответить на вопрос».
- С помощью
мы получили поисковые запросы для нескольких тысяч таких диалогов.
- Обучили
-модель на ответах AI-тренеров.
- Дальше было много циклов active-learning:
- находили примеры неудачных рефразов. Например, это диалоги, в которых Нейро выдавал ответ в стиле «ничего не нашлось»: такое часто происходило именно в результате неправильной переформулировки;
- собирали для них правильные рефразы;
- переучивали модель.
В сумме мы собрали более десятка тысяч таких рефразов с помощью AI-тренеров.
Поиск источников
До этого этапа мы сформировали поисковый запрос, который поможет Нейро найти документы для решения задачи пользователя. Сознательно упрощу и расскажу очень поверхностно эту часть схемы, потому что хочется вписаться в разумный размер статьи и рассказать самое главное. Возможно, в будущем опишу всё детальнее.
Поиск источников можно поделить на три этапа.
Первый из них — стандартный для Яндекса. Давайте «просто» найдём самые релевантные запросу пользователя документы в интернете. Тут под капотом работает самый обычный Яндекс Поиск.
Второй этап. Давайте выделим из топа релевантных документов текстовую информацию, на основе которой может быть построен ответ. В среднем в одном документе содержится 4000
, но почти всегда можно выделить полезный фрагмент текста значительно меньшего размера без потери информации. Это позволит использовать больше документов в итоговом ответе без увеличения времени ответа и нагрузки на GPU.
Эта задача значительно сложнее, чем может показаться на первый взгляд. Рассмотрим алгоритм на примере одного документа.
- Возьмём текст документа.
- Разобьём его на блоки длиной 256 токенов, при этом делаем так, чтобы они пересекались. Это нужно, чтобы не потерять важную информацию, которая могла оказаться на стыке двух блоков.
- Поскорим блоки по релевантности запросу с помощью очень маленькой BERT-модели (8 слоёв). Кстати, эта же модель исторически используется для создания быстрых ответов в Поиске.
- Выбираем самые релевантные блоки, пока не наберём 1500 токенов уникального текста.
- «Склеиваем» выделенные блоки в том же порядке, в котором они появились в исходном тексте.
На
третьем этапе надо выбрать пять документов, на основе которых будет построен ответ. Нюанс в том, что не любой хороший документ подходит для использования в Нейро. Например, если вы ищете рецепт, то видео может быть очень хорошим ответом в поиске, но текстовой информации там не содержится, а значит, для генерации ответа Нейро оно не подходит.
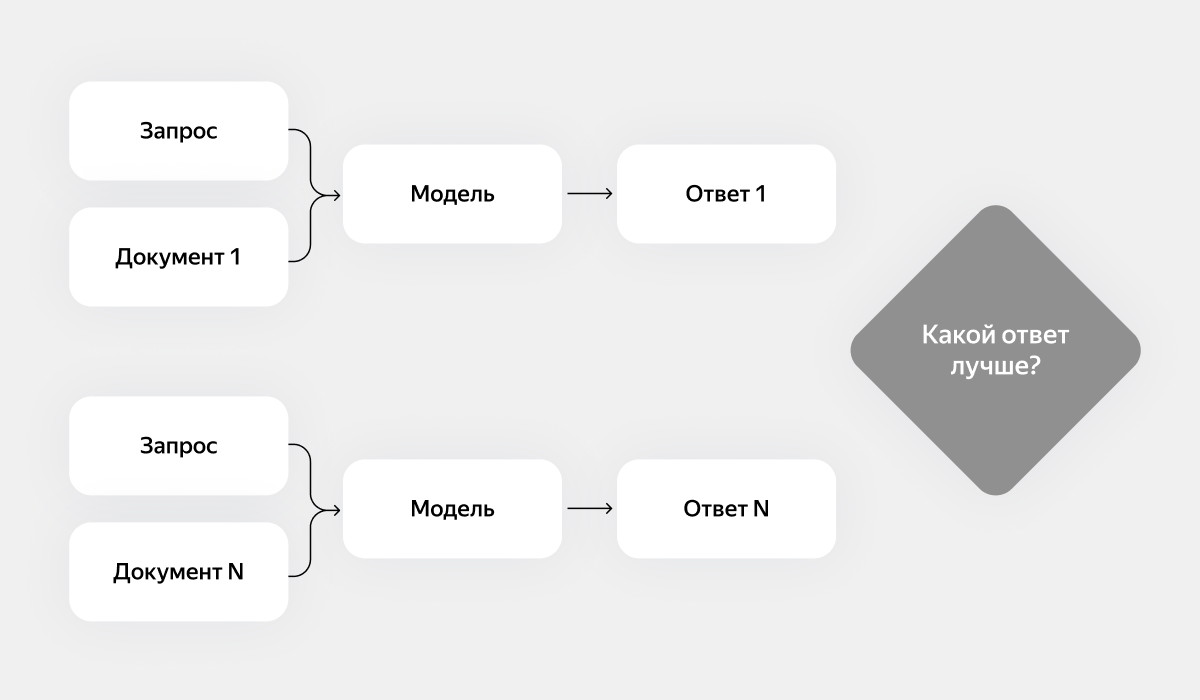
Идея тут следующая. Предположим, что у нас есть reward-модель — она умеет автоматически оценивать, хороший получился итоговый ответ на вопрос или нет. Тогда те документы, которые приводят к хорошим ответам на запрос, лучше, чем те, которые приводят к плохим. Цель — сделать модель-предиктор того, сможет ли генеративная модель ответить на вопрос пользователя на основании документа.
В рамках этой идеи мы сгенерировали большой датасет, включающий в себя запросы, документы, ответы модели на основе документов и оценки reward-модели. Далее мы обучили модели Сatboost (на поисковых факторах) и BERT (на текстах документов), которые по запросу предсказывают, текст какого документа лучше на него ответит. С помощью них Нейро выбирает пять документов для формирования ответа.
Хорошо, но почему мы выбираем пять документов? Чем больше документов во входе, тем меньше каждый последующий несёт пользы. Качество ответов, сформированных по одному и двум источникам, может различаться кардинально. При этом между пятью и шестью источниками разница уже не так существенна. Но каждый следующий источник существенно увеличивает потребление вычислительных ресурсов. Мы решили взять пять документов в ответ и вместить их в 8000 токенов на входе в модель. Это такой баланс между качеством ответа, скоростью его генерации и потреблением GPU-ресурсов.
Генеративная модель
Наконец, мы собрали все входные данные для того, чтобы сгенерировать хороший ответ на вопрос пользователя! И вот тут-то начинается основной челлендж.
Суть проблемы такая. Представьте, что у вас есть самая лучшая базовая GPT-модель общего назначения (не только наша, мы для теста пробовали разные варианты). Она умеет неплохо решать любые задачи. Но нам в продукте не нужны любые задачи, нам нужно хорошо решать одну конкретную задачу. Для этого у модели должны быть отлично развито множество нужных нам свойств. Например, способность удерживать конкретный формат ответа, не терять ссылки на источники информации, не использовать факты, взятые из памяти модели. Добиться всех этих и других свойств от модели общего назначения можно и с помощью промпта с очень подробным описанием задачи. Но качество ответа в таком случае оказывается недостаточным, мы хотим лучше. А значит, надо учить специализированную модель.
Общая схема обучения модели выглядит так:
Сначала опишу схему целиком, а потом расскажу детальнее про внутренние блоки. Итоговое обучение модели выглядит так.
- Возьмём несколько тысяч запросов и составим для них идеальные ответы с помощью AI-тренеров.
- Обучим SFT-модель на ответах.
- Возьмём десятки тысяч запросов, для каждого из них сгенерируем множество пар ответов с помощью модели.
- Для каждой пары разметим с помощью асессоров (специалист, выполняющий разметку по инструкции), какой ответ лучше, а какой хуже.
- Некоторые ответы раскрасим с помощью разметки подтвержденности (найдём враньё).
- На этих разметках обучим reward-модели.
- Возьмём десятки тысяч диалогов и на каждый из них сформируем по несколько сотен вариантов ответа, используя различные версии генеративной модели и семплируя с разными температурами.
- Скорим ответы с помощью reward-моделей.
- Запускаем rejection sampling (SFT на лучший по reward ответ). Цель этого этапа — обучить новую модель, которая видела большое количество только хороших ответов. Тут важно научиться генерировать хорошие ответы. Reward используется для фильтрации плохих ответов.
- Поверх модели из предыдущего шага запускаем несколько стадий DPO. Это не самый простой алгоритм, но он уже стал стандартным, поэтому его я описывать не стану. Цель этого этапа — не только улучшить генерацию хороших ответов, но и перестать генерировать плохие (например, не соответствующие формату, содержащие враньё, грамматические или логические ошибки).
Для того чтобы вся ML-схема успешно завелась, требуется, чтобы составные компоненты схемы были сделаны хорошо.
Датасет запросов
На запросах из этого датасета модель понимает, как надо отвечать. Если запросов какого-то типа не окажется, то и модель не научится на них отвечать. Например, если в датасете нет диалоговых запросов, в которых вопрос — это уточнение ответа на предыдущий вопрос пользователя, то модель не научится держать контекст диалога.
Поток задач определяет, на какие вопросы мы должны отвечать хорошо, а какие нам менее важны. Хочется, чтобы датасет был достаточно разнообразен и покрывал все нужные нам срезы целевого потока. То есть мы должны угадать, с какими запросами к нам придут пользователи после релиза, и научиться отвечать на них уже сейчас. Если мы научимся отвечать только на поток запросов в текущий поиск, то никакой дополнительной ценности пользователю мы не принесём.
Есть два больших класса задач, на которые нам нужно фокусно смотреть.
- Сложные запросы, на которые текущий поиск отвечает недостаточно хорошо. Например, когда ответ надо скомпилировать из разных источников или он «размазан» в длинном тексте статьи.
Мы отобрали 200 тысяч обезличенных запросов из поискового потока. Отфильтровали лишнее, оставив только запросы, в которых пользователь хотел узнать информацию (не посмотреть видео, не купить, не перейти в соцсеть, …). Далее с помощью асессоров по отдельно написанной инструкции выделили эти сложные запросы. Их оказалось примерно 5%
- Диалоги. При сборе диалогов возникает классическая проблема курицы и яйца. Изначально модель не умеет поддерживать диалоговый контекст. Чтобы её научить, нужно собрать датасет диалогов. И тут есть целый ряд условий.
- Диалоги не должны быть искусственными. Иначе модель не научится отвечать на настоящие вопросы людей.
- Диалоги должны вестись на основе ответов именно модели Нейро. Например, диалоги с навыком «Алиса, давай придумаем» гораздо менее полезны для задач Нейро. Причина в том, что модель должна научиться работать с уточнениями на свои же ответы.
В итоге мы собрали диалоги (с уточнениями на исходный запрос) используя
. Потом обучили первую версию нашей модели, используя эти диалоги.
Далее итеративно:
- AI-тренеры чатились с последней версией модели;
- мы собирали эти логи;
- переобучали модель получше.
И так несколько раз.
Идеальные ответы
Чтобы обучить первую SFT-модель, от которой будет отталкиваться всё решение, нужно получить много тысяч отличных ответов на самые разные вопросы. Причём качество тут важнее количества.
Но у нас была проблема. AI-тренер может потратить на хороший ответ несколько часов (потому что нужно погрузиться в тему достаточно глубоко). А идеальных ответов для обучения нужно тысячи. И относительно быстро. Но такого числа хорошо подготовленных AI-тренеров просто нет. Что делать?
Для начала опишем, как у нас устроен процесс сбора ответов для обучения модели. Для каждого вопроса есть тикет, для каждого ответа — вики-страница с историей всех правок и комментариев. Можно сказать, что мы воспринимаем каждый ответ как код, который подобно разработчику пишет AI-тренер. Мы хотим уметь тестировать такие ответы, как и код, который мы пишем. Для текста таким тестированием выступает разметка качества и подтверждённости, о которых более детально расскажу чуть ниже.
Если разметки говорят, что ответ плохой, то мы его «дебажим». Возможны три случая: если ошибся тренер, то фиксим его ответ; если это ошибка разметки, то чиним разметку; а если принципы составления ответов расходятся с принципами разметки, то исправляем что-то из этого (и с таким мы часто сталкивались). То есть мы не только правим ошибки в текстах, но и находим ошибки в самом процессе.
А теперь переходим к нашему решению проблемы. Мы даём те же самые задачи асессорам. Их значительно больше, но их ответы не всегда получаются хорошими. Ответы мы также пропускаем через разметку. Оставляем хорошие, а плохие отдаём AI-тренерам на исправление. Исправить ответ обычно проще, чем составить с нуля. Так мы масштабируем работу AI-тренеров и с вовлечением асессоров получаем тысячи хороших ответов для обучения модели в разумные сроки.
Разметки
К сожалению, очень часто в ML-среде этапу сбора данных уделяется недостаточно внимания. Фокус делается на архитектуру и размер моделей. Но фактически значительную часть времени работы над Нейро заняло именно создание и улучшение разметок.
Разметка представляет собой процесс аннотирования данных, присвоения им меток или категорий. В нашем случае это оценка отдельных аспектов качества и подтверждённости текстового ответа.
Разметки позволяют формализовать продуктовое видение, перевести его в формат конкретной инструкции и оцифровать отдельные ключевые аспекты. Чем более точно сформулирована инструкция для разметки, чем ближе она соответствует продуктовым ожиданиям, тем проще и эффективнее становится работа ML-разработчиков.
Разметка качества
Мы разбиваем задачу оценки качества ответа на четыре подзадачи. Мы называем их аспектами качества.
- Полезность. Ответ даёт нужную информацию в удобном для восприятия виде.
- Безопасность. В ответе нет очевидно вредной или опасной рекомендации.
- Подтверждённость. Если необходимо, ответ подтверждён ссылками на источники информации.
- Компетентность. Ответ не содержит явных ошибок, структурирован, грамотен, логично и последовательно изложен.
Для каждого из этих аспектов мы создали пятибалльную шкалу и описали чёткие критерии для каждой оценки в каждом аспекте. Сначала асессор получает два ответа. Каждый из ответов оценивает по пятибалльной шкале по каждому аспекту. Потом для каждого аспекта выбирает, какой ответ ему кажется лучше, и лишь затем на основе этих оценок асессор ставит итоговый вердикт по каждому из ответов и говорит, какой из них лучше.
Оценки 1 и 2 мы считаем провальными. Если ответ получил хотя бы одну такую оценку в любом из аспектов, мы считаем, что итоговая оценка не может быть выше неё. Если все оценки от 3 до 5, тогда итоговая оценка ставится экспертным мнением асессора.
Данная схема позволяет собирать много полезных данных. Позволяет искать хорошие и плохие ответы в потоке, позволяет объяснять причины этих оценок. А попарные сравнения позволяют лучше обучать модели. Вместо двух ответов с одинаковой оценкой мы получаем, что один ответ всё же лучше другого и модель может к нему двигаться.
Сейчас у нас 1500–2000 асессоров участвуют в создании этой разметки.
Разметка подтверждённости
Важное свойство наших ответов в том, что они всегда подтверждены источниками и их достоверность всегда можно проверить. А ещё за счёт сносок легко проверить, откуда модель взяла информацию для ответа. Это настолько важное и сложное свойство, что мы выделили его в отдельную разметку, в дополнение к той, что есть в разметке качества.
Мы научили асессоров не просто бинарно отвечать на вопрос: «Верно ли, что ответ подтверждается источником?», мы собираем информацию про каждый кусочек этого ответа. Мы умеем отличать прямое цитирование документа от логического вывода, умеем отличать правильный вывод от ошибочного и так далее. Сейчас у нас есть почти 500 асессоров, с помощью которых мы собираем эти данные.
Это ОЧЕНЬ сложная разметка, её построение заняло у нас почти полгода. К хорошему решению мы пришли не с первой попытки. Ниже наглядный пример разбора.
Запрос пользователя: «Сколько обычно значений у многозначного фразеологизма? Чем по этому признаку многозначный фразеологизм отличается от многозначного слова?»
Каждая такая раскраска сопровождается текстовым комментарием с пояснениями. Вот комментарий для раскраски из примера:
Второй блок — искажение, прямо опровергается {тут название источника}: “Большинство слов русского языка, как уже было сказано, многозначны; большинство фразеологизмов, наоборот, однозначны”. Выделила весь блок целиком, потому что само по себе “как и слов” не выглядит как утверждение.
В источнике 1 не говорится, что многозначных фразеологизмов меньше. Из остальных утверждение скорее выводится, чем содержится (источник 2: “Большинство фразеологизмов отличается однозначностью”, источник 3: “Многозначность фразеологизмов … возможна. Но следует отметить, что встречается она не так уж часто”).
“Однозначные фразеологизмы…” — {тут название источника}: в источнике говорится “ …во многих отношениях фразеологизмы ближе к слову, чем к словосочетанию: в большинстве случаев фразеологизм равен слову по своему значению, является его эквивалентом”. Это выглядит как исходный пункт ошибочного вывода
Вместо заключения
Нейро — это во многом новый для Яндекса и непривычный для пользователей подход к поиску ответов на вопросы. При его разработке мы объединили наш опыт в создании поисковых технологий и генеративных нейросетей. Надеюсь, что этой статьёй мне удалось показать, какой большой труд нашей команды скрывается за маленьким переключателем в поисковой строке.
Версия, которую вы можете попробовать сегодня, — это, конечно же, только первый шаг. Нам предстоит ещё очень много работы, продукт будет активно развиваться. И ваши отзывы помогут нам сделать Нейро ещё более полезным инструментом.